DS) Feature Engineering/dtype/replace/apply
2022. 7. 28. 18:20ㆍDS/EDA_Data
Feature Engineering 은 창의성과 도메인지식을 바탕으로 데이터셋에 존재하는 feature을 통해서 새로운 feature을 생성해내는 작업입니다.
예를 들어보자면, 섭씨의 온도를 화씨로 바꾼다던지, 키와 몸무게 등을 통해 비만도라는 새로운 컬럼을 생성하던지 하는 작업들을 의미한다.
기본적으로 data를 불러온 이후, 해당 데이터에 대해서 살펴보아야 한다.

df.dtypes
df.info()
df.isna().sum()다음과 같은 명령어들을 통해 몇 가지 볼 수 있는데 컬럼별 내부 데이터의 타입이라던지, 결측치(missing value)등이 확인 가능하다.
아래의 코드를 이용해서 새로운 컬럼을 추가 가능하다. 이는 feature engineering의 예시라고 보면 된다.
df['j_val'] = df['ROE(%)'] + df['ROA(%)']

String to Num
데이터를 보다 보면 숫자를 나타내는데 있어서 천 단위마다 ","를 이용해서 표현한 데이터들이 많다. 이를 적절하게 제거하는 방법을 알아보자.
먼저 변수 하나에 저장되었을 경우 해결법을 보고 이 해결법을 토대로 DataFrame에서는 어떻게 적용시킬지를 보겠다.
a = '123,400'
b = a.replace(',','')
print(b,type(b))
b = int(b)
print(b,type(b))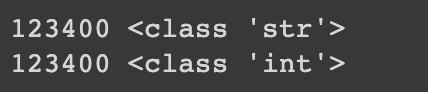
replace를 통해서 ','를 제거해준 것을 볼 수 있다. 이걸로 끝이 아니라 타입 또한 int/float 형태로 만들어줘야 사용하기 용이하다.
그러면 이를 DataFrame에서는 어떻게 적용 시킬 수 있을까?
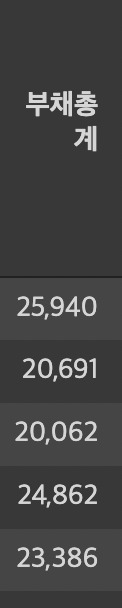
해당 데이터를 숫자형태로 바꾸려면 apply를 이용하면 해결 할 수 있다.
def mknum(string):
return int(string.replace(',',''))
df['부채총계'] = df['부채총계'].apply(mknum)
df['부채총계']
'DS > EDA_Data' 카테고리의 다른 글
| DS) Data Manipulation (0) | 2022.07.29 |
|---|---|
| DS) EDA/pre-processing (0) | 2022.07.28 |