2022. 7. 29. 17:09ㆍDS/EDA_Data
merge/ concat/ condition/ melt/ pivot_table
데이터를 분석하는데 있어서, 초기 우리가 얻은 데이터가 과연 입맛대로 이쁘게 만들어져 있을까?
대부분의 경우 그럴일은 없다. 데이터 수집/제공 하는 곳에 따라서 다양한 형태로 데이터가 저장되어 있을 것이다. 그렇기에 이런 데이터를 우리가 다루기 좋은 형태로 만들 필요성이 있다. 그에 따라 앞서 datatype을 수정하는 등 전처리/EDA를 진행한다.
이번에는 데이터가 각각 다른 파일에 저장되어 있는 경우 어떻게 다루어야 할 지 알아보자.
기본적인 개념은 집합을 더한다는 느낌으로 이해하면 받아들이기 쉽다.

빨간 부분의 데이터는 missing value로 처리 될 것이다. 두 DataFrame에 대해서 col 혹은 row 에 따라서 합쳐지는 모습을 보자.
pd.concat([df1, df2]) ## df1,df2 = dataframe
x = pd.DataFrame([['AX','AY'],['BX','BY']], index = ['A','B'], columns = ['X','Y'])
y = pd.DataFrame([['AX','AZ'],['CX','CZ']], index = ['A','C'], columns = ['X','Z'])
a = pd.concat([x, y]) ## concate_by_row
b = pd.concat([x, y], axis = 1) ## concate_by_column
print(a)
print(b)
데이터를 합치는데 있어서 concat 과 더불어 많이 사용되는 merge가 있다.
merge

merge의 기본 개념은 공통된 부분을 이용해서 합쳐주는 것이다.
실제로 데이터에 대해서 어떻게 concat 과 merge 가 다른지 보자.

사용될 데이터프레임은 다음과 같다.
pd.concat([df,df2], axis = 1)
df.merge(df, how = 'inner' , on='종목')
눈에 보이는 차이점은 7번째 row의 존재유무이다. Concat에서는 missingval로 채워지면서 생겼지만, merge의 경우 완전히 겹치는 (교집합) 부분에 대해서만 생성이 된것을 볼 수 있다. 이는 단순 merge의 특징이라기 보다는 merge의 parameter인 how를 통해서 결과물이 달라진다. 기본베이스df.merge(붙일 df, how=' 붙이는 방식' , on='기준') 의 형태로 merge를 사용한다. 그러면 how 에는 어떤 값들을 넣을 수 있는 걸까?

이해하기 쉽게 초록색이 다 들어있는 df에 대해서는 Nan값을 생성하지 않는다고 생각하자.
다시 말해서 left의 경우 기본베이스 df에 있는 모든 내용과 붙일df에 대해서 결합시키나 Nan값을 만들지는 않겠다는 의미이다.
condition
데이터를 단순히 합치거나 특정조건에 맞춰서 결합하는 방법은 알았다. 그러면 이제 생성된 거대한 데이터에서 내가 원하는 데이터만들 보고 싶으면 어떻게 해야 할까?
조건1 : 테마는 주류
조건2 : 매출액은 5,000 이상
이에 대해 True값을 갖는 df를 반환 시키려면 이와 같이 사용하면 된다. (한 가지 방법만 있는 것이 아니다.)
Groupby
이번에는 같은 테마 별로 매출액의 평균을 구해보겠다. 이는 Group by 에 대한 개념을 이해하기 위함임을 알고 보자.
df.groupby('테마').매출액.mean()
보면 알겠지만, groupby는 동일한 변수값에 대해서 데이터를 모아주게 된다.
Styling
결과물에 대해서 꾸미고 싶은 생각이 혹시나 든다면,
데이터프레임의 형태를 시각적으로 보기 좋게 만드는 스타일링 방법도 존재한다.

다만 github에 올라가면 보이지 않음을 유의하자.

각 라이브러리 마다 원하는 데이터의 형태가 있다.
무슨 말인가 하면, 라이브러리가 input으로 데이터를 받을 때 처리하기 용이한 데이터의 형태가 있다는 뜻이다. 단순히 datatype을 의미하는 것이 아니라 어떤 형태의 table이 들어오는지를 의미할 수 도 있다. seaborn에서는 tidy 형태의 table을 선호하는 경우가 많은데
Tidy data가 뭔지 알아보자
Tidy data
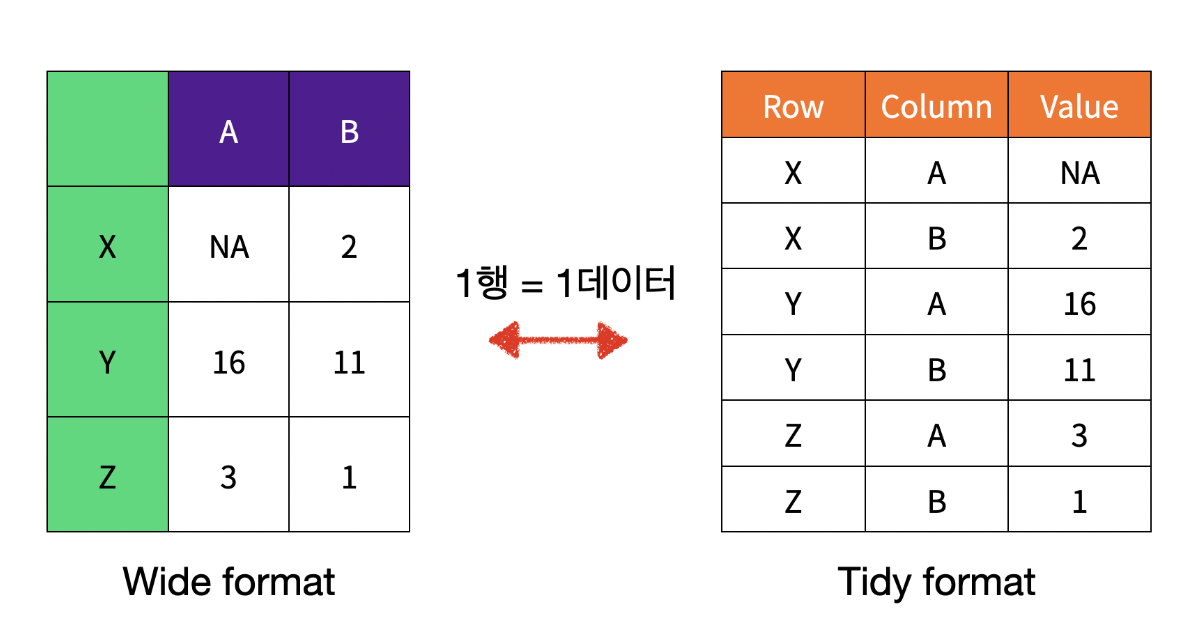
조금만 생각해 보아도 다음 데이터들이 어떻게 다른지 알 수 있다.
예를 들어서 wid format의 경우 한 행에 x라는 사람의 키와 몸무게를 한번에 보여주는 반면, Tidy format은 한 행 마다 x라는 사람의 신체정보를 하나씩 보여주는 형태라고 볼 수 있다. (키,몸무게는 예시일 뿐)
두 형태를 자유자재로 다루기 위해서는 어떤 함수를 이용해야 할까?
바로 melt / pivot_table이다.
먼저 melt를 보자
melt

id_vars : 하나의 관측치의 대상
value_vars : 관측하고자 하는 부분
Pivot_table
이번에는 반대로 tidy to wide 를 보자.

그런데 tidy date를 만들면 좋았던 것일까?
실제 seaborn을 통해서 결과를 보면서 알아보자.

다음과 같이 이쁘게 그래프를 그릴 수 있다.
Ref.

codestates
'DS > EDA_Data' 카테고리의 다른 글
| DS) Feature Engineering/dtype/replace/apply (0) | 2022.07.28 |
|---|---|
| DS) EDA/pre-processing (0) | 2022.07.28 |